
















解决方案



仪器平台






伯豪生物服务科技创新,平均2天协助客户发表一篇SCI文章!

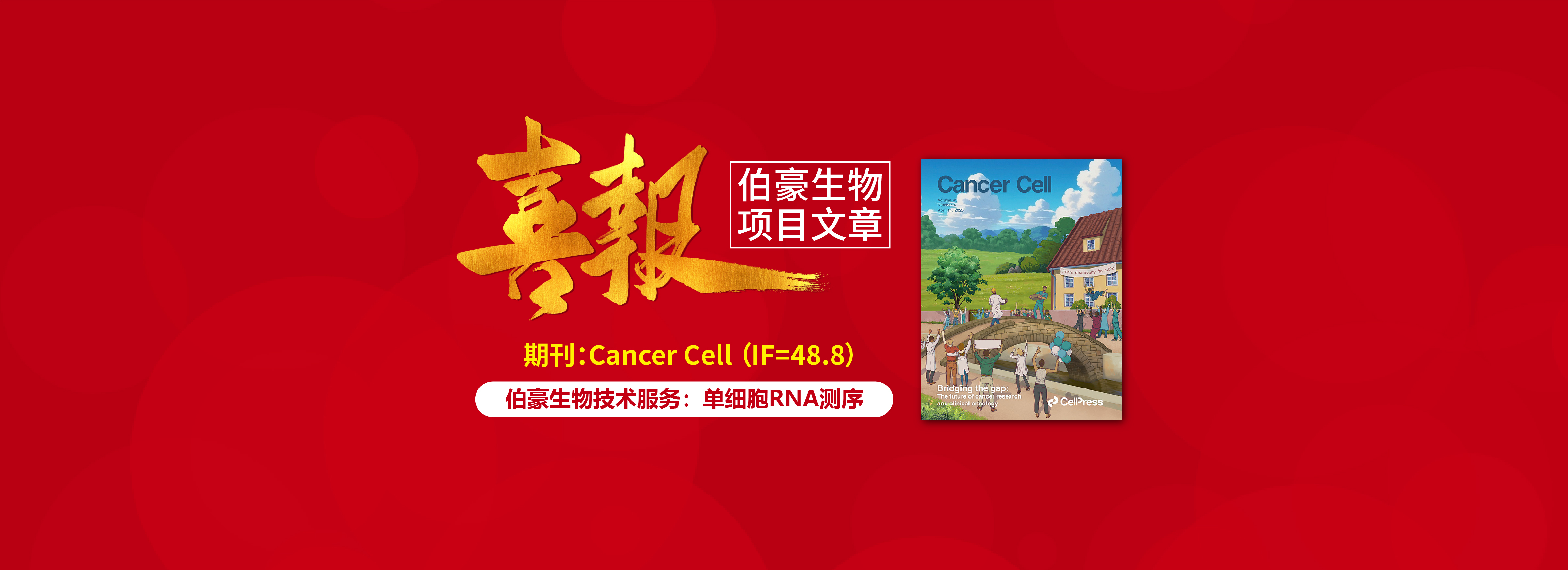
Pan-Cancer Human Brain metastases Atlas at singlecell resolution
发表期刊:Cancer Cell | 影响因子:48.8| 伯豪生物:单细胞RNA测序项目服务
查看详情
Liver type 1 innate lymphoid cells develop locally viaan interferon-y-dependent Loop
发表期刊:Science |影响因子:44.7 |伯豪生物:单细胞测序项目服务 |合作客户:中国科学技术大学田志刚院士团队
查看详情
An extra-erythrocyte role OF haemoglobin Body inchondrocyte hypoxia adaption
发表期刊:Nature| 影响因子:64.8| 伯豪生物:mRNA-Seq项目服务| 合作客户:空军军医大学张丰、孙强团队| 研究结论:首次发现软骨细胞一种全新的细胞耐受缺氧机制。
查看详情
Single-Nucleus Transcriptome Profiling OF Locally Advanced Cervical Squamous Cell Cancer Identifies Neural-Like Progenitor Program Associated with the Efficacy OF Radiotherapy
发表期刊:Advanced Science| 影响因子:15.1| 伯豪生物:单细胞核转录组测序
查看详情
SCUBE2 mediates Bone metastasis OF luminal breast Cancer by modulating immune-suppressive osteoblastic niches
发表期刊:Cell Research| 影响因子:46.297| 伯豪生物:单细胞测序
查看详情
Inherent hepatocytic heterogeneity determines expression and retention OF edited F9 alleles Post-AAV/CRISPR infusion
发表期刊:PNAS| 影响因子:12.779| 伯豪生物:单细胞测序
查看详情
Brain single-nucleus transcriptomics highlights that polystyrene nanoplastics potentially induce Parkinson’s Disease-Like neurodegeneration by causing energy Metabolism disorders in mice
发表期刊:Journal Of Hazardous Materials| 影响因子:14.224| 伯豪生物:单细胞测序
查看详情
关于上海伯豪生物技术有限公司
上海伯豪生物技术有限公司(简称:伯豪生物,英文名:Shanghai Biotechnology Corporation)2008 年 12 月成立,是生物芯片国家工程研究中心的有机组成部分,专注于提供专业的生物医药和疾病诊断创新技术、产品和优质服务。伯豪生物自成立以来获得了国家基因检测技术应用示范中心、国家工信部专精特新“小巨人”企业、院士专家工作站、高新技术企业、上海市研发公共服务平台(负责“上海市高通量疾病标志物服务平台”和“上海市基因芯片专业服务平台”的运营)、上海市服务外包公共平台、上海科技小巨人企业、浦东新区企业研发机构、联合实验室建设等一系列资质,拥有医疗机构执业许可证、医疗器械经营许可证。
了解更多+

共同探讨单细胞多组学技术在复杂疾病机制研究中的应用前景
26
2025-11
-
2025-11-25
-
2025-11-19
-
2025-11-07
合作伙伴
<















