转录因子(Transcription Factors, TFs) 指能够以序列特异性方式结合 DNA 并且调节转录的蛋白质。转录因子通过识别特定的 DNA 序列来控制染色质和转录,以形成指导基因组表达的复杂系统。尽管众多科学家对理解转录因子如何控制基因表达有着浓厚的兴趣,精准定位转录因子在基因组上的特异性结合位点,以及转录因子结合后如何参与转录调节仍然具有挑战性。

本综述主要涵盖了 1600 多种可能的人类转录因子和与其中三分之二转录因子结合的 motif,来鉴定转录因子并对其功能进行注释。本文根据目前对转录因子及其功能的理解,为思考转录因子如何单独又如何作为整体工作提供了思路。
转录因子是对基因组的直接阐释,是执行 DNA 解码序列的首步。许多转录因子充当着主调节因子和选择基因的角色,控制着细胞类型的决定、发育模式和特定途径控制(如免疫反应)的过程。在实验室中,转录因子可以促进细胞分化、去分化和转分化。转录因子和转录因子结合位点突变是人类致病的主要因素。在后生动物中,他们蛋白质序列调控区的生理作用通常非常保守,这表明基因组调控" 网络 "可能同样是保守的。但是,个别监管序列的转换率很高,当时间尺度更长时,转录因子可能会发生多拷贝和突变。相同的转录因子可以调节不同细胞类型中的不同基因(例如,乳腺和子宫内膜细胞系中的 ESR1),这表明即使在同一生物体内转录因子的调节也是动态的。确定转录因子如何以不同方式组装以识别绑定位点和调控" 网络 "转录是一项庞大而令人望而生畏的工作,但是,对于理解它们的生理作用、解码基因组的特定功能,以及在复杂生物中绘制高度特异性表达程序的编排是至关重要的。
相对于其他序列,转录因子对特异性结合序列具有 1,000 倍甚至更高的偏好,因为转录因子可以通过阻断其他蛋白质的 DNA 结合位点进而发挥作用(例如,经典的 lambda,lac 和 trp 阻遏物),单独结合特定 DNA 序列的能力通常被视为调节转录能力的指标。如果没有转录因子结合的 DNA 序列的详细信息,就不能在功能上理解这些蛋白质。转录因子与特异性 DNA 结合通常概括为“基序”(motif),是指给定 TF 优先的相关短序列组的模型,其可用于扫描较长序列(例如,启动子)以鉴定潜在的结合位点。确定 DNA 结合的 motif 通常是详细阐释转录因子功能的首步,鉴定潜在的结合位点为进一步分析提供了途径。在过去的十年中,我们开发 motif 和基因组结合位点的能力得到了显着提高,从而产生了关于 TF-DNA 相互作用的前所未有的大量数据。为了开发目前的 TF 目录,本文主要参考了 TRANSFAC,JASPAR,HT-SELEX,UniPROBE 和 CisBP,以及先前的人类转录因子目录。
早在 20 世纪 80 年代,就描述了真核生物中的主要 TF 家族,如 C2H2- 锌指(ZF),同源域,碱性螺旋 - 环 - 螺旋(bHLH),碱性亮氨酸拉链(bZIP)和核激素受体(NHR)。通常通过诸如 DNA 酶足迹法或迁移率变换的方法鉴定结合位点,再使用 N - 末端肽测序,噬菌体文库或单杂交筛选鉴定特定结合蛋白。继续通过实验方法鉴定(例如,单杂交测定,DNA 亲和纯化 - 质谱,和蛋白质微阵列可以筛选新的 DNA 结合蛋白),但是今天,大多数已知和推定的 TF 已经通过先前表征的 DNA 结合结构域(DBD)的序列同源性来鉴定,这也用于对 TF 进行分类。目前在蛋白质数据库(PDB)中可获得大约 100 种已知的真核生物 DBD 类型。迄今为止,除了少数充分表征的哺乳动物转录因子之外的所有转录因子都含有已知的 DBD。在仅基于与 DBD 的同源性匹配来推断功能时必须小心,因为并非所有结构域都一定会结合特定 DNA 序列。
首先根据结合位点中每个碱基的转录因子的相对偏好产生一张基础表或“位置权重矩阵”(PWM)。在每个碱基位置,四个碱基中的每一个都具有得分,并且将序列的每个碱基的这些得分相乘来预测得到转录因子对该序列的相对亲和力。在许多情况下,这反映了对一个或少数相关序列的强烈偏好。此外,PWM 还存在一些缺点:基线位置之间可能存在依赖关系由于 DNA 形状或可变形性;转录因子可以具有多种结合模式(例如,蛋白质的不同物理构型导致分离的,不同的基序)等。为了解释这些复杂性,科学家们开发了更复杂的模型,例如结合了对二核苷酸和高级 k -mers 的偏好,使得转录因子及其家族的准确性有所提高。然而,在许多情况下,改进的效果很小甚至检测不到。PWM 仍然是分析转录因子结合常用的模型,并术语“motif”来表示 PWM。
接下来通常通过实验确定的结合位点和与 motif 匹配的序列之间仅存在部分重叠,甚至实验确定的结合位点是相对较差的预测因子。同时,motif 匹配通常是 ChIP-seq(染色质免疫沉淀测序)数据集中富集的序列之一,表明内在 DNA 结合的特异性对于体内转录因子的结合是重要的。出现这样的现象不是空穴来风,大多数转录因子结合位点很小(通常是 6 -12 个碱基),并且是灵活的,因此典型的人类基因(> 20 kb)将包含大多数转录因子的多个潜在结合位点。因此我们需要通过其它途径来解决问题,例如转录因子之间的协同性和协同作用,为这种特异性缺陷提供了一个现成的解决方案。大多数人类的转录因子必须共同努力才能完成任何事情,但是他们之间的相互作用和关系的细节大多数是未知的。结合 DNA 后转录因子的生物化学作用也在很大程度上未被反映出来。因此,解码基因调控如何与 TF 结合基序和基因序列相关仍然是一个主要的现实层面的挑战。
理论论证和实践观察表明,后生动物的转录因子一般必须共同作用才能与 DNA 结合,在效应功能中达到所需的特异性。转录因子有多种合作方式,例如帮助相互结合 DNA(协同结合)或通过不同机制影响染色质状态或转录(协同调节)。TF 还可以作为同二聚体(例如,bZIP 和 bHLH),三聚体(例如,热休克因子)或更高级结构协同结合。
协同结合可以通过几种方式发生。当它由蛋白质 - 蛋白质相互作用介导时容易理解,当两个(或更多个)相互作用蛋白质以相容的间隔和方向结合 DNA 时,便赋予其额外的稳定性。高通量体外研究表明,协同结合常常影响复合物中转录因子的序列偏好,并且还可能对两个结合位点之间的间隔序列产生限制。单分子成像的结果研究证实,当多个转录因子结合在一起时会占据更长时间。
近期的研究表明 DNA 介导的协同结合也在转录因子功能中起重要作用。分子建模和结构分析表明,在某些情况下,协同性是由于 DNA 促进了蛋白质之间的接触。在其他情况下,蛋白质结合在 DNA 的对立面或彼此相对较远的一边,表明 DNA 直接介导了协同性。也就是说,一个转录因子的结合以促进另一个转录因子结合的方式影响 DNA 的形状。
为了与核小体 DNA 结合,TF 必须与核小体竞争或以某种方式与核小体或核小体 DNA 相互作用以进入其位点。TF 也可内在地与核小体竞争结合 TF,此外,一些 TF 可以启动核小体的置换或至少改变它们的构象。这些 TF 的活性也可能取决于它们结合核小体 DNA 的能力,这可能受核小体上结合位点的旋转定位的影响(例如,Yamanaka 因子 POU5F1,SOX2,KLF4 和 MYC)。另一个有趣的现象是,不同的染色质重塑器具有特定 DNA 序列和 / 或核小体构象的偏好,表明核小体和核小体的定位机制赋予了 TF 功能上额外的 DNA 序列特异性。
转录因子在与 DNA 结合时影响转录的方式变化很大。一些转录因子(例如,TBP)可以直接 RNA 招募聚合酶,还有一些可以招募促进特定转录阶段的辅助因子。大多数真核生物的转录因子被认为通过招募辅助因子起作用。这种“共激活因子”和“辅阻遏物”初期被鉴定为转录因子效应子活性的介质,通常是大的多亚基蛋白质复合物,或通过几种机制调节转录的多结构域蛋白质。它们通常涉及染色质结合,核小体重塑和组蛋白或其他蛋白质结构域的共价修饰。IFNβ 增强体是共激活因子招募的一个经典例子,其中多个转录因子的结合导致 GCN5 / KAT2A 和 CBP / p300 组蛋白乙酰转移酶的募集。由此产生的局部染色质环境变化会引起核小体重塑,如 SWI / SNF 复合物为 RNA 聚合酶创造空间以结合并启动转录。一些共激活因子和辅阻遏物似乎更广泛。p300 经常被用作增强子的标记物,与数十种 TF 相关联。连接 TF 和 RNA 聚合酶 II 的 Mediator 复合物类似地与数千个基因座相关联。
特异性的效应结构域通常可以介导 TF 特异性辅助因子的招募。同样,核激素受体的配体结合结构域以配体和背景依赖的方式促进与共激活因子、辅阻遏物和其他 TF 的相互作用。经大量研究后,发现蛋白质中存在的经典转录激活因子序列(例如,TP53,E2F 和 SP1 中发现的酸性序列),它们通常是非结构化的低复杂性序列,具有称为短线性基序的小功能区域。
TF 传统上被归类为“激活物”和“阻遏物”;然而许多 TF 根据所在序列的位置和辅助因子的作用可以招募具有相反作用的多种辅助因子,例如,MAX 作为与 MNT 或 MXD1 作为异二聚体与 DNA 结合时起抑制剂作用,当作为异二聚体与 MYC 结合时起激活作用。目前还没有全面的辅助因子目录。此外,基因激活或增强子和启动子之间的通信所需的生化功能在很大程度上仍然是未知的。人体中多达 443 种不同的染色质修饰蛋白已经做好了归类,并且已经了解了辅助因子和染色质蛋白之间的许多相互作用。但是,相同的研究检测到很少的 TF,这表明 TF- 辅助因子的相互作用是弱的 / 瞬时。
目前并没有一个通用的解决方案可以自动生成我们所需要的列表,因此当下结构域无法高精度地推测出转录因子,文库又是高度不统一的,电子信息的注解有没有一个统一的标准。新的人类转录因子库发表于 2009 年,总共涵盖了 535 个人的转录因子,并描述了所推测的 DBD。近年来,该文库迅速扩展。本综述对人类转录因子集进行了一定程度的修订。
本综述手工查询了 2,765 种蛋白质,为每种蛋白质创建了一个网页,其中包含所有相关信息和外部数据库的链接。本综述考虑了全局序列比对和 DNA 已知的结合的残基,以便在仅有亚基结合 DNA 的家族(例如,ARID,HMG 和 Myb / SANT)中对表征不佳的蛋白质做一个评估。考虑到可行性的因素,我们没有搜索或记录蛋白质修饰或结合配偶体等复杂性。 “HumanTFs”网站(http://humantfs.ccbr.utoronto.ca/)显示结果,每个 TF 都有一个单独的页面,以及每种 DBD 类型的所有已知 motif 和信息以及序列比对。此网站还有一个用户可以选择提交其他信息的选项。

Table1. 判断和识别 TF 特异性结合的实验方法
记录的 1,639 个已知或潜在的人类转录因子,其中大多数至少包含了两种 DBD 类型中的一种(C2H2-ZFs 和 Homeodomains)。剩下近一半(46%)是另外六个 bHLH、bZIP、Forkhead、核激素受体、HMG / Sox 和 ETS(图 1B)。在考虑了缺乏 DNA 序列特异性的已知亚类后,含有 Myb / SANT 和 HMG 结构域的 TF 比先前估计的少得多。1,639 个 TF 中的大多数(93%)或作为单体与 DNA 结合或作为同源多聚体与 DNA 结合。且许多都包含相同 DBD 类型的多拷贝(图 1C),但其中大多数是 C2H2-ZF,它们与 DNA 按列结合(图 1A)。每种蛋白质的 C2H2-ZF 数量变化很大,一定程度上取决于效应结构域(图 1B)。含有 KRAB 的亚型中的大量 C2H2-ZF 可能是由于靶向单个转座子所需的特异性。只有一小部分 TF(47 或〜3%)含有多种类型的 DBD,而 POU 是常见的同源域是常见的(图 1C)。大多数人类 TF 也含有其他蛋白质结构域(图 1D):其中有 391 种不同类型的非 DNA 结合结构域,与 TF 效应子功能的多样化和广泛网络的概念一致。
当前的 TF 列表可能仍然不完整,完整的 DBD 系列可能仍然未被完全发掘。实际上,由于缺乏规范的 DBD,此列表中的 69 个 TF 被归类为“unknown family”。大多数这些蛋白质缺乏 motif(见下文),晶体结构基本上是无法获得的,并且与 DNA 结合的证据仅包括在单个文库中鉴定的少数序列。因此,在获得更多实验数据结果前,应谨慎对待此类别的 TF。
此外,一些已知的 DBD 系列可能比目前所理解的更大。例如,根据 Interpro 和 SMART 数据库,预测的简单的 AT 钩结构域(由 13 个氨基酸 [aa] 共有序列表示)分别存在于 3 和 21 号人类基因中。然而,一个更宽泛的定义,只需要在 22 个碱基窗口上存在侧翼为多个碱性残基的 GRP 三肽(Aravind 和 Landsman,1998),它存在于数百种人类蛋白质中,每种蛋白质都可以代表真正的 TF。C2H2-ZF 家族也值得评估,因为出现了更好的模型来识别这些短的(〜23 aa)结构域,并将参与 DNA 结合的那些区域与促进与 RNA 或其他蛋白质相互作用的区域区分开来(Brayer 和 Segal,2008)。
Figure1. 人类转录因子合集
目前大约四分之三(1,211)的人类转录因子具有与其结合的 motif。已知 motif 中的 913 个是通过体外高通量法(例如 HT-SELEX 或 PBM)测定出来的。图 1B 说明大多数类别的 TF 具有高或完全的 motif 覆盖,而少数具有主要差异。例如,几乎所有的同源结构域(188/196)都有一个已知或推断的 motif,可能是由于它们相对容易在体外研究,它们的深层次的特点能够通过同源性推断。相比之下,C2H2-ZF 类转录因子目前缺少数百个 motif(267/747)(图 1B),可能是因为它们难以在体外研究(许多是大蛋白),而且保守的相对较少。
许多 TF 识别相似的 motif,通常对应到 TF 家族或亚家族,这个现象与许多先前的研究一致(图 2A)。值得注意的是,C2H2-ZF 蛋白为 motif 中多样性的(图 2B),这与先前所研究得结构和 DNA 接触残基的多样性一致。图 2C 显示的是 NHR 家族的 motif,说明转录因子多样性涉及单体 DNA 序列偏好和蛋白质复合物形成的变化。图 2C 中的许多 motif 被二聚体识别。在人体中总共有超过 500 个特异性的 motif,表明广泛的 DNA 序列可以作为转录因子结合位点。
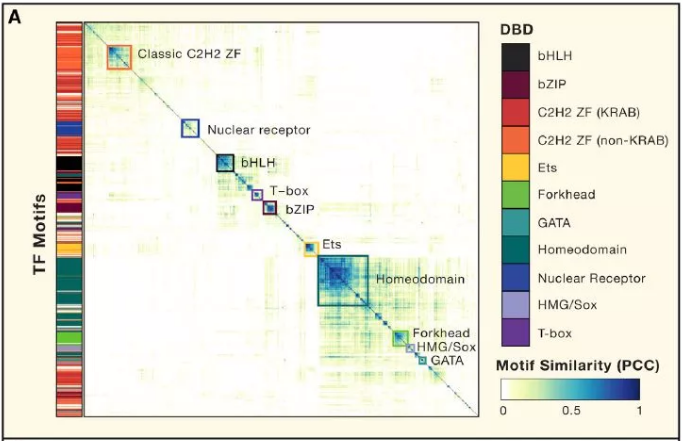
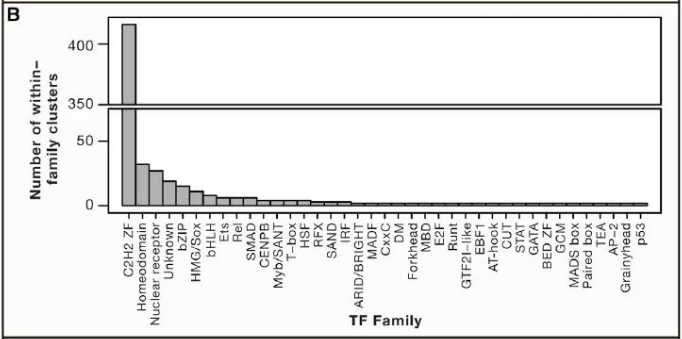
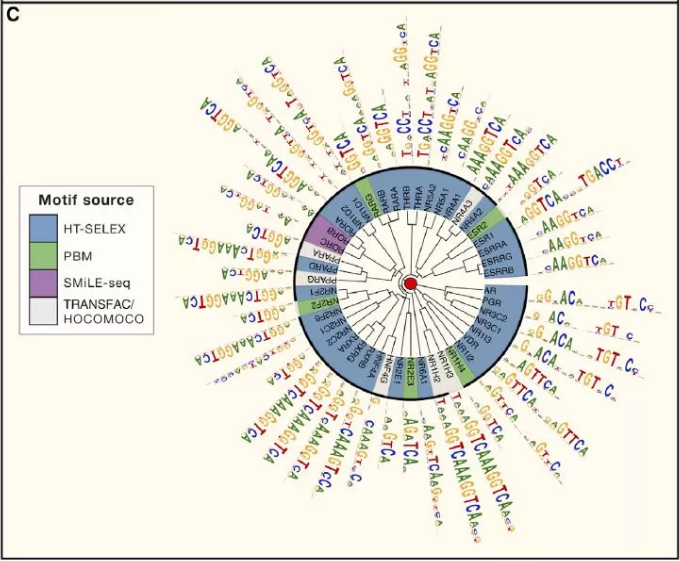
Figure2. 特异性结合人类转录因子的 DNA
转录因子的演变通常比它们的调控位点的演变慢得多。人和果蝇之间的转录因子直系同源物通常显示出几乎相同的序列特异性。尽管如此,转录因子确实在不断进化,它们的 motif、结合物和表达模式都在不停地改变着。人类转录因子中不变与改变中的一个突出例子便是大多数哺乳动物基因组编码了数百种含有 KRAB 的 C2H2-ZF 蛋白,其中许多都显示出了多样化选择的标志,在人和小鼠之间也具有复杂的直系同源模式。在人类中,KRAB C2H2-ZF 蛋白通常都与转座子(TEs)(主要是 LINE 和内源性逆转录病毒)结合,在初期可能是通过抑制 KRAB 结构域的功能使它们沉默。转座子和转录因子之间的“军事竞赛”为其迅速而又多样化的变化做出了很好的解释。
基于它们在真核基因组中的分布(图 3A),当前的 1,639 个转录因子根据亲缘关系得知其涵盖了包括脊椎动物,四足动物,胎盘哺乳动物或灵长类动物在内的后生动物主要群体。有趣的是,几乎所有脊椎动物都具有同源域蛋白的可识别对应物,而几乎所有哺乳动物特异性蛋白都含有 C2H2-ZF 结构域。实际上,Ensembl 定义的人类 TF-TF 旁系同源物之间的分化都有两种趋向:两侧对称动物中多种 TFs 家族出现了首波重复,由 KRAB C2H2-ZF 主导的第二波重复则出现在 Amniota(图 3B,左)。早期时整个多样性的 TF 家族的复制与脊椎动物中整个基因组发生两轮复制的假说一致。该事件与细胞类型的多元化发展是大致符合的,并且复制的 TF 可能有助于调控新细胞类型。KRAB 的辐射性增加可能在一定程度上解释了为什么胎盘能够很大可能的传递逆转录病毒。值得注意的是,在过去的 3 亿年里,KRAB 的辐射区域中 TF-TF 的复制主导了其在所有人类同源物的分布(图 3B,右)。
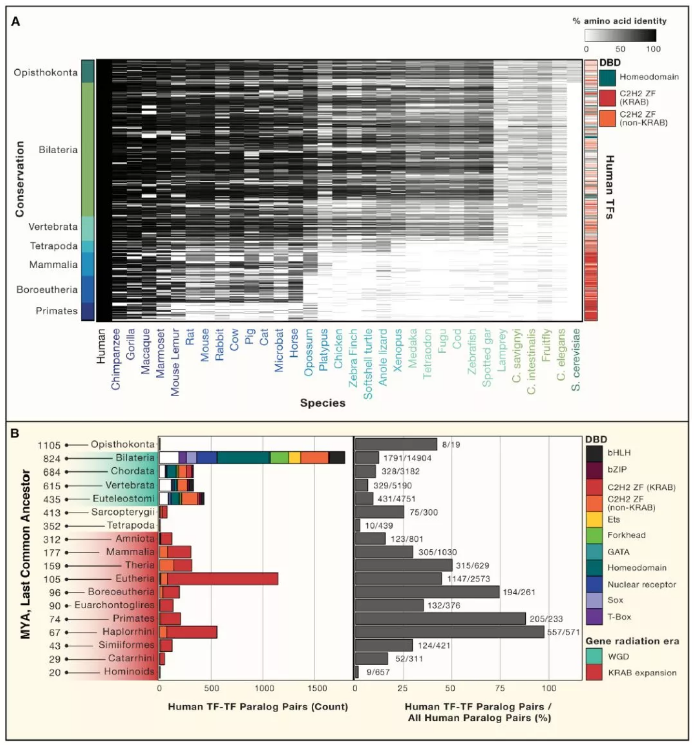
Figure3. 人类转录因子的直系同源基因和旁系同源基因
基因(包括转录因子)的组织和细胞类型包括 TFs 的特异性表达通常对应着相应的特定功能。我们使用来自人类组织图谱中的 RNA-seq 数据检查了在 37 个成人组织中的 1,554 个转录因子的表达模式(图 4A),采用其组织特异性表达的定量定义。这种基因表达模式的全局视图捕获了许多特征明确的 TF 的已知作用。例如,SOX2,OLIG1 和 POU3F2(OCT7)几乎只在大脑皮层中表达,而 GATA4 和 TBX20 仅在心肌中高度表达。该数据集中大约三分之一(543)的人类 TF 表现出组织特异性表达的特点,其中包括许多具有不良特征的生理作用。
在其他的 TF 家族中,一半(49%)是具有组织特异性的,并提供了关于其特定生理功能的线索。更高分辨率的数据,例如来自单细胞 RNA-seq,可以解析同一组织的不同类型细胞对转录因子间的联系,使得对于细胞鉴定和受转录因子调控的基因有更深刻的理解。
转录因子占所有人类基因的约 8%,并且与多种疾病和表型相关。转录因子突变通常是高度有害的,这也解释了为什么基因组 TF 编码位点富含超保守的位点。转录因子遗传分析可能因基因调控网络固有的功能冗余而变得复杂,因为表型可能难以仅在特定条件下检测得到或表现出来,或者因为在群体水平上具有高度有害作用的变体不存在。尽管如此,关于临床表型中人类 TF 的全球视角确实揭示了一个共同的主题。图 4B 展示出了编码 TF 的基因内或附近的大量突变相关的人类疾病表型。对于与先天性生长激素缺乏有关的垂体前叶发育不全观察到了观察到大量基因的富集。已知的 15 种基因参与该表型,其中有 12 种是编码 TF(p<10 -11),包括多个同源域和 Sox 家族的转录因子。总的来说,人 313 个(19.1%)的转录因子至少与一种表型相关,显着高于所观察到的部分(16.2%)。相比之下,基于近期的 CRISPR 筛选的数据(3% 对 10%),转录因子从人类癌细胞系中的核心必需基因组中排除,可能是因为人类的转录因子库已主要用于发育或组织功能特定化。
一些多基因疾病的全基因组关联研究(GWAS)信号也富集了基因座编码的转录因子(图 4C)。这些疾病中的很多都具有强烈的免疫依赖性,表明许多免疫反应相关的转录因子所具有的突出作用。此外,许多独立的转录因子基因座具有针对多种疾病的强 GWAS 信号。例如,编码 Ikaros 基因家族 C2H2-ZFS 的基因座中,突变体 IKZF1 和 IKFZ3,在适应性免疫应答中起到了至关重要的作用。
转录因子的模块化结构有助于突变影响的机制的识别。DBD 突变会改变序列特异性,位于 DBD 之外的突变也可能对基因表达产生很大的影响。在癌症中,染色体异常可以产生具有新功能的癌融合蛋白,例如 Ets 因子 ERG 和 FLI1 与 RNA 结合蛋白 EWSR1 融合。同样的,对于任何基因,在控制 TF 表达的调节区内的突变,导致 TF 功能改变。例如,在驱动 MYC 表达的增强子中弱化 TCF7L2(TCF-4)结合位点可降低结肠中肿瘤发生的风险。
转录因子作为一类独特的基因,它们的结合位点会受所调节的 DNA 的变异或突变影响。目前发现了许多这样的例子,其中涵盖了大量的的转录因子家族疾病。更深入地了解转录因子对于如何找到对应目标并控制基因表达模式对于我们了解 85%-93% 的常见疾病相关的遗传变异有极大的帮助。
基因组中的大多数的功能性 DNA 都是具有调节性的,转录因子在其的识别和功能发挥中起着核心作用。在许多人类疾病中 TFs 有着明显的作用,使得理解转录因子所介导的基因调控机制的重要性更加突出。目前所面临的挑战依然存在,包括解决调节相同基因的多种元件之间的协同作用和冗余,预测增强子 - 启动子的联系,沿染色体及其三维结构上大规模调控的特点,以及各种类型的表观遗传记忆。解决这些挑战的计算机方法是正在进行中,开发探索转录因子在成核和调停的实验技术同样也在进行着。这些进展将有助于我们达到下一个人类遗传学前沿:以 TF 的方式解码基因组。

Figure4. 人类转录因子的功能特性
参考文献
Lambert SA, Jolma A, Campitelli LF, Das PK, Yin Y, Albu M, Chen X, Taipale J, Hughes TR, Weirauch MT. The Human Transcription Factors. Cell. 2018;175:598–9.

本文来源于网络:如侵权,请邮件提示删除,接收邮箱:market@shbio.com
